Building a own POSIX compatible Distributed File System with Netty
Let us build our own resilient distributed storage (file) system with support for storing and retreiving files in chunks just like HDFS.
Such distributed storage systems can be used for developing applications like Dropbox that allows storing video files.
In the next article, we will extends this DFS for video specific file storage like Youtube, Netflix.
Requirements:
Non Functional Requirements:
- Parallel retrievals: Large files will be split into multiple chunks. Client applications should retrieve these chunks in parallel using threads.
- Probabilistic Routing: to enable lookups without requiring excessive RAM, client requests will be routed probabilistically to relevant storage nodes via bloom filters.
- Interoperability: The DFS will use Google Protocol Buffers to serialize messages. This allows other applications to easily implement the wire format.
- Asynchronous Scalability: Non-blocking I/O should be used to ensure the DFS can scale to handle hundreds of active client connections concurrently.
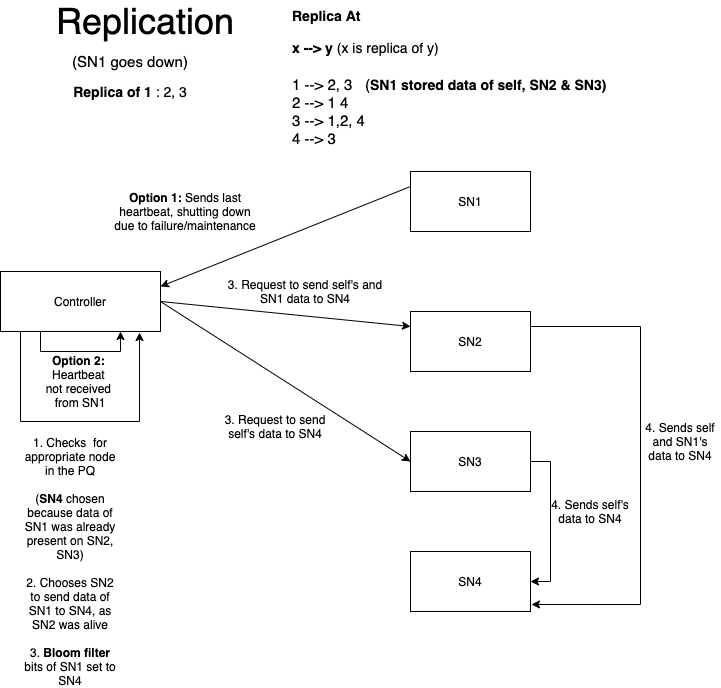
- Fault tolerance: The system must be able to detect and withstand two concurrent storage node failures and continue operating normally. It will also be able to recover corrupted files.i.e support Read Repair
- POSIX Compatibility: Unlike many other DFS, this DFS will be POSIX-compatible, meaning that the file system can be mounted like any other disk on the host operating system.
Why do we need a Distributed File System?
We could have simply connected different storage systems with network to develop a Network File System:
What if we need compute along with storage: To do some processing, within a server.
Advantages of having a memory:
Use it for caching
Use it for in-memory data processing
It allows to connect different computers on different networks.
We could use NFS-Ganesha (used by GlusterFS)
NFS vs DFS
https://www.edureka.co/community/3136/difference-between-hdfs-and-nfs
Other than fault tolerance, DFS like HDFS does support multiple replicas of files. Data Recovery.
Because the storage is Cheap, we can afford to have multiple replicas on different systems.
This eliminates (or eases) the common bottleneck of many clients accessing a single file. Since files have multiple replicas, on different physical disks, reading performance scales better than NFS.
Ref
Storage Model
Block Storage
-
Block storage chops data into blocks and stores them as separate pieces.
-
Why Block Storage?
It decouples the data from the user’s environment and spreads it across multiple environments that can better serve the data.
Unlike file storage, block storage doesn’t rely on a single path, files can be retrieved quickly with block storage.
Back of the envolope estimation:
We assume our DFS will be read heavy. The read to write ratio will be around 100:1.
Capacity Estimattion
We assume the DFS to be location in one geographical region in a single data center.
Requests per second
asfa
Storage for x years based on size of 1 object (GB/TB/PB)
asfa
Memory Estimate (Caching for hot data) (GB/TB/PB)
asfa
Network Bandwith Estimation
New Data per second (Write): test
URL Clicks/Redirection( Read): test
Incoming Data/Traffic (Write): test
Outgoing Data/Traffic ( Read): test
Storage for x years (Write): test
Memory for Cache (Write): test
System Interface Definition
- What is expected from the System
- CLI
- APIs : user_dev_key
Defining the data models
- Storage, Transportaion, Encrption
High Level Design
Datanode
Namenode
System Components
- Controller
- Storage Node
- Client:
Controller
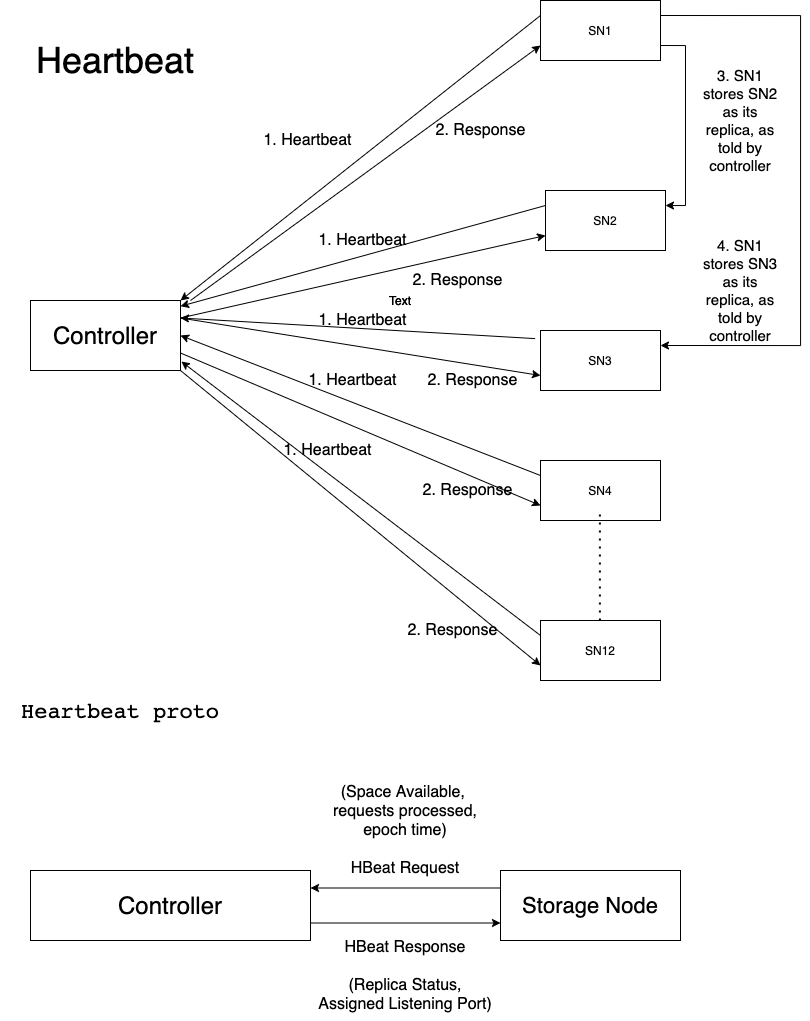
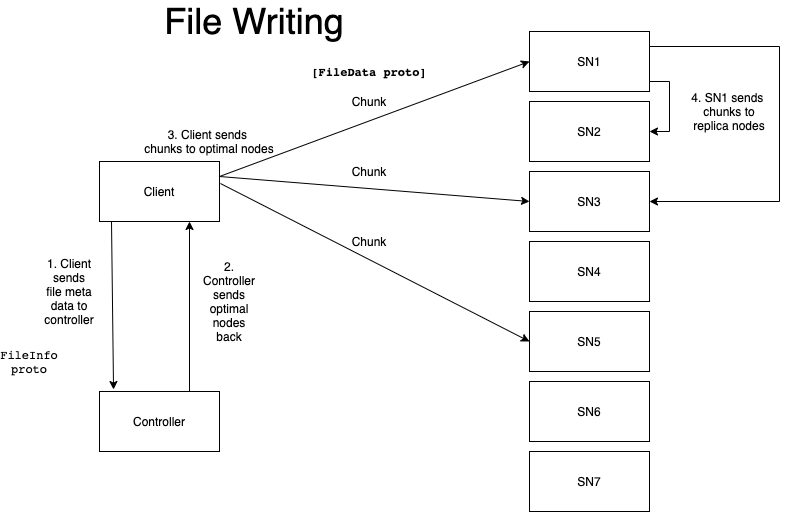
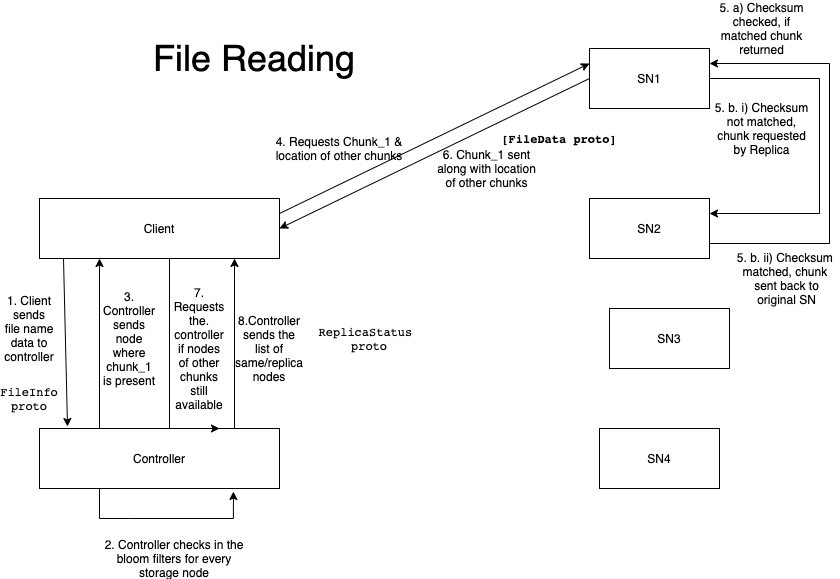
The Controller is responsible for managing resources in the system, somewhat like an HDFS NameNode.
- When a new storage node joins the DFS, the first thing it does is contact the Controller.
more...
At a minimum, the Controller contains the following data structures:
-
A list of active storage nodes
-
The file system tree, describing the directories in a file system but NOT the files.
-
A routing table for each directory in the file system tree with one or more bloom filters for probabilistic file lookups
Since this is probabilistic, the
Controller will not know exactly where files are stored, but it will be able to route requests to their correct destination with a low probability of false positives.
Storage Node
Storage nodes are responsible for storing and retrieving file chunks.
- When a chunk is stored, it will be checksummed so on-disk corruption, it can be detected.
more...
- When a corrupted file is retrieved, it should be repaired by requesting a replica before fulfilling the client request.
- Metadata, such as checksums, should be stored alongside the files on disk.
Client
The only functionality with the client is to store and retreive the files.
The client should be unaware of any operations that are being carried out at the Controller and the storage node
Bloom Filters
Planning the Design
Molestiae cupiditate inventore animi, maxime sapiente optio, illo est nemo veritatis repellat sunt doloribus nesciunt! Minima laborum magni reiciendis qui voluptate quisquam voluptatem soluta illo eum ullam incidunt rem assumenda eveniet eaque sequi deleniti tenetur dolore amet fugit perspiciatis ipsa, odit. Nesciunt dolor minima esse vero ut ea, repudiandae suscipit!
#2. Creative WordPress Themes
Temporibus ad error suscipit exercitationem hic molestiae totam obcaecati rerum, eius aut, in. Exercitationem atque quidem tempora maiores ex architecto voluptatum aut officia doloremque. Error dolore voluptas, omnis molestias odio dignissimos culpa ex earum nisi consequatur quos odit quasi repellat qui officiis reiciendis incidunt hic non? Debitis commodi aut, adipisci.

Detailed Design
Why Netty?
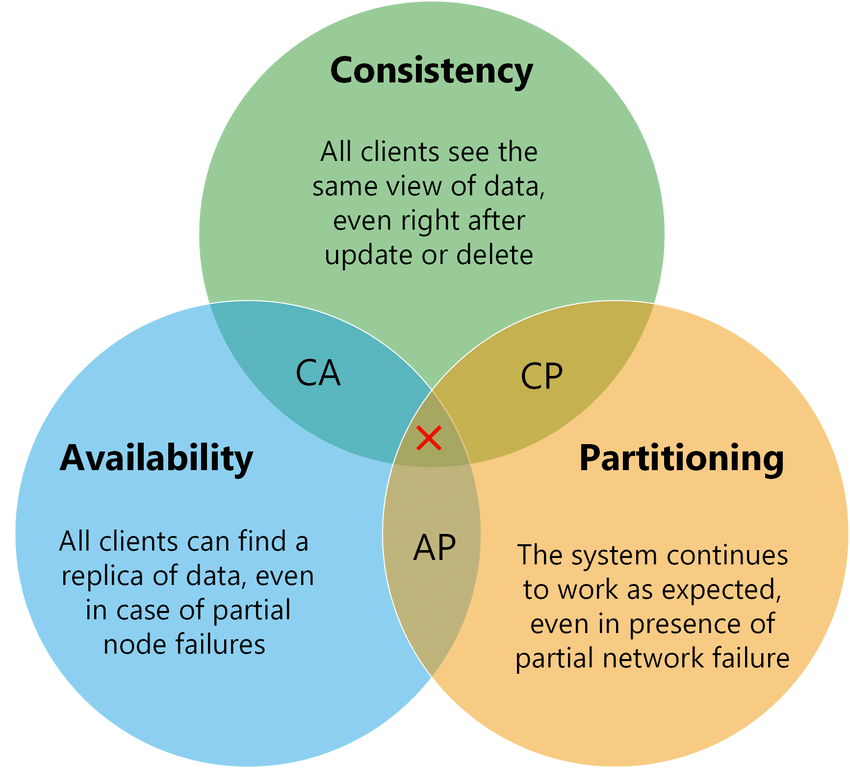
CAP Theorem:
We will focus on Availability and Partition tolerance over Strong/Strict Consistency.
 Copyright: Create own image
Copyright: Create own image
- Consistency: Our DFS will follow Eventual Consistency model.
- Availability: We assume that the data will be always available, irrespective of any number of node failure. But, there should be atleast 3 nodes availble.
- Partition tolerance:
Partitioning Tolerance:
Horizontal Vs Verical Data Partitioning
Tradeoffs:
Bloom Filters
Our bloom filters will use
murmur3 hashing algorithm.
MurmurHash is a non-cryptographic hash function suitable for general hash-based lookup.
Why MurmurHash algorithm.?
When
compared with other hash algorithms,
the MurmurHash algorithm takes the least average time hashing, even with higher number of collisions.
Also, when working with Random UUIDs, it still takes the least time, when compared with its competitors like
FNV-1,
DJB2 or
SuperFastHash.
More about
Murmur3 hash algorithm.
The MurmurHash 3 is preferred over MurmurHash 2 because even if
MurmurHash 2 computes two 32-bit results in parallel and mixes them at the end, which is fast but means that collision resistance is only as good as a 32-bit hash.
Murmurhash3 allows a 128-bit variant, which might be more along the lines of what he's looking for (the original post mentions SHA256).
Why Protocol Buffers.?
Protocol Buffers vs Avro
Identifying and Resolving the bottlenecks
Identifying Single Point of Faliure
Resolving the bottlenecks
Once completed, request Prof. Mathew for proof reading.
Ayush Arora
Software Developer with years of experience designing, developing and implementing highly scalable systems.
Currently, learning to build large-scale Data Processing systems on the cloud (GCP & AWS) using Hadoop and Spark.
